Content Migration
When redesigning a website or simply moving to a new CMS, migrating content is a core task. If you or your client authored hundreds or thousands of article over years, there is no way that you can migrate those by copy & pasting from one CMS to another.
No more database
If your old CMS had a database and your new CMS doesn’t, you need to figure out a way to migrate content from database tables to folders and files. In my case, I didn’t even have access to the database (neither did I want to mess with Drupal anyway).
Migrating without database access? Scrape it!
The good news was that each page on the website output a lot of structure meta data and the content was formatted as simple paragraphs with nothing fancy in between.
Given the structure of the HTML, it seemed very reasonable to migrate content by first scraping it from the website.
- Scrape the content from the website
- Format the content and meta data to match the new content structure
- Generate Markdown files
Why scraping?
- Need to migrate a website to a flat file CMS, like Statamic or Kirby
- No access to the original database of a website
- No knowledge of the current CMS
- No easy way to export from the current CMS
- No way to import content into a flat file CMS other than creating files
Why not use the Statamic Importer?
While the importer can handle a collection of JSON content and generate entries from it, it has a drawback:
- no support for multi-lingual content
{kind=link}
In my case, it was necessary to import entries in German and French, thus I had two options:
- use my poor PHP skills to hack around with the importer to support multiple languages
- generate .md files and copy them to the content folder (one folder per language)
Scraping
Without this library for NodeJS, this project would have not been possible. The sitemap-generator is intended to generate a XML Sitemap for a website and does so fairly well! Simply pass it a base URL and start the generator.
https://github.com/lgraubner/sitemap-generator
const SitemapGenerator = require("sitemap-generator");
const baseUrl = "https://your-base-url.com/some-path";
const generator = SitemapGenerator(baseUrl, {
stripQuerystring: false
})In order to generate the sitemap, the script crawls the entire website with all the links between the pages.
But instead of waiting for the script to finish and output the XML, I’ve used the callback function every time a new link is being added to the sitemap.
// register event listeners
generator.on('add', (url) => {
// new link found
});
Parsing
Now, whenever we receive a new URL, we can fetch the URL and wait for the response which will be a string of HTML.
Using the library JSDOM we can then turn the string into a in memory document object model (DOM) that acts like a real DOM.
// Construct a new in-memory DOM from the HTML string
let document = new jsdom.JSDOM(htmlString).window.document;This allows us to use querySelectors etc. to parse anything from each document. For example meta-tags, title, body content, …
For example, to receive the meta description, we can use:
document.querySelector("meta[name='description']").content;When querying actual HTML content, such as an article, we might want to strip some of the HTML. We could:
- use innerText and remove any HTML / formatting
- use innerHTML and convert it to Markdown
The benefit from converting to Markdown is that line breaks and some formatting like bold, italic and headings are preserved.
I’ve used Turndown for this task.
https://github.com/domchristie/turndown
var TurndownService = require("turndown");
var turndownService = new TurndownService();
let node = document.querySelector("article");
let markdown = turndownService.turndown(node.innerHTML);From all the queried information, we can then construct objects for each URL:
let data = {
url,
title,
description,
markdown,
...
}And ultimately collect all those chunks of data in an Array or Object which we can save to disk once the scraper is done.
fs.writeFile(output, JSON.stringify(collection), function(err) {
if (err) {return console.log(err);}
console.log("The file was saved!");
})Transformation
Okay, it’s simple to get the data as JSON. But some flat file content management systems require markdown files in YAML format.
Fortunately, there is JS-YAML for that.
https://github.com/nodeca/js-yaml
Using this library, we can reformat the JSON to match the intended structure and then write individual files for each entry of the original collection.
yaml.safeDump(entry, { lineWidth: Infinity });I’m not sure anymore if the lineWidth parameter is required, but it can help to avoid unnecessary line breaks when converting text to YAML.
Strip whitespace, control characters, etc.
When copy & pasting content from PDF to a CMS, editors might actually copy invisible control characters. While invisible to the reader, a converter like JS-YAML might get into trouble.
From my experience, it meant that paragraphs and new lines where output as literal “\n” which is not how a human would make a new line in markdown. I did ran a few regex before converting to YAML.
For example to replace some invisible whitespace with nothing:
processedText.replace(/•/g, "");Note: The • character is used to represent an actual invisible character.
Generating Markdown files
I then saved all the files with a specific format using the original publish date and slug.
German entries went into the root of the folder, French entries into a “fr” subfolder.
It was important that I both files shared the same UUID. For Statamic this must be a UUID/4.
{kind=link}
Once I figured out that I can’t just use any ID (like “123”), I simply switched to assigning each entry a UUID.
https://github.com/uuidjs/uuid
const uuidv4 = require('uuid/v4');
uuidv4(); // ⇨ '1b9d6bcd-bbfd-4b2d-9b5d-ab8dfbbd4bed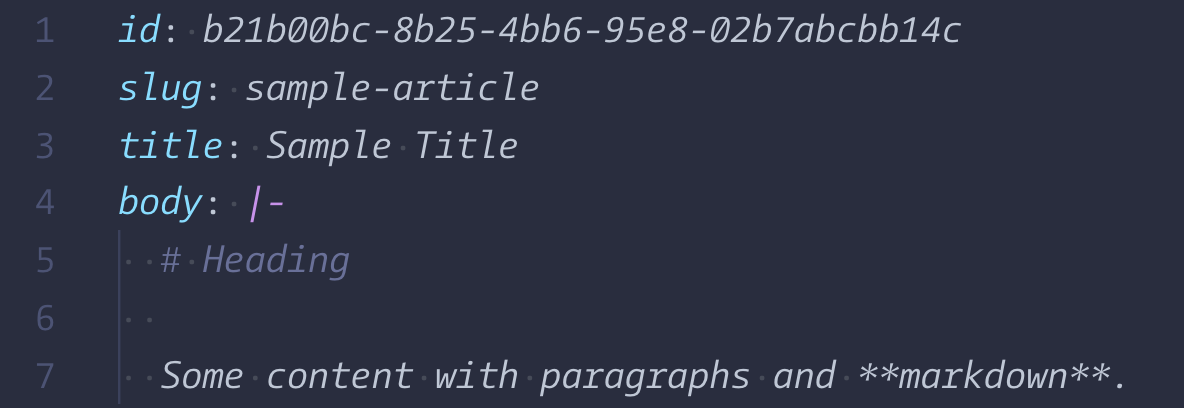
After running the script, it generated hundreds of markdown files, neatly organized in one folder per language, ready to import!

Summary
While there aren’t many steps and code involved, there were a few details that I had to figure out along the way. Once I had a nice big chunk of JSON with all the content, it was clear to me that this could be transformed into any structure required by the CMS.
I initially hoped that the Importer could do its magic by feeding it the JSON, but it turned out that it didn’t support multi-language content. Thus, I had to re-format the data, convert it to YAML and mess around with hidden white space, control characters and the like, but finally it worked out!